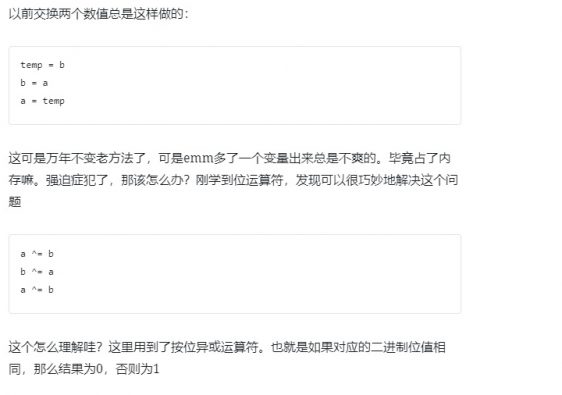
这段时间在学机器学习,花了两天时间利用paddle框架手撕了几大图像分类模型:
- LeNet
- AlexNet
- VGG
- GoogLeNet
- ResNet-50
有一说一,还是有很大收获的(尽管中间在训练调参的时候踩坑了,这个放到文末讲)。
这里使用到了眼疾识别数据集iChallenge-PM,是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。
数据集下载地址:https://aistudio.baidu.com/aistudio/datasetdetail/19065
数据集的图片
iChallenge-PM中既有病理性近视患者的眼底图片,也有非病理性近视患者的图片,命名规则如下:
- 病理性近视(PM):文件名以P开头
- 非病理性近视(non-PM):
- 高度近视(high myopia):文件名以H开头
- 正常眼睛(normal):文件名以N开头
我们将病理性患者的图片作为正样本,标签为1; 非病理性患者的图片作为负样本,标签为0

图像分类的流程

LeNet
LeNet的网络结构如下(输入的shape形状是手写数字识别的,本任务中已经改成了224*224*3)

然后,我尝试在LeNet上进行训练:
class LeNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层块,每个卷积层使用sigmiod激活函数,后面跟一个2x2的池化
self.conv1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
self.fc1 = Linear(in_features=300000, out_features=64)
# 第二个全连接层输出神经元个数为分类标签的类别数
self.fc2 = Linear(in_features=64, out_features=num_classes)
def forward(self, x, label=None):
x = self.conv1(x)
x = F.sigmoid(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.sigmoid(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.sigmoid(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
x = F.softmax(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
然而,得到的结果却不令人满意:



从上面的图表可以看到,随着训练迭代次数的增加,模型在训练集和测试集的准确率并没有明显的上升,甚至由于过拟合导致了准确率的降低。损失函数的大小下降的幅度也很小。因此,LeNet在较大的图片上的表现并不好。
AlexNet
AlexNet是Alex Krizhevsky等人提出的,并且在2012年ImageNet比赛中,以很大优势获得了冠军。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和三层全连接,同时使用了下面的这三种方法改进模型的训练:
- 数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
- 使用Dropout抑制过拟合。
- 使用ReLU激活函数减少梯度消失现象。

在眼疾筛查的问题上,对应的网络实现代码:
class AlexNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(AlexNet, self).__init__()
# AlexNet与LeNet不同的是激活函数换成了Relu
self.conv1 = Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv4 = Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv5 = Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.max_pool5 = MaxPool2D(kernel_size=2, stride=2)
self.fc1 = Linear(in_features=12544, out_features=4096)
self.drop_ratio1 = 0.5
self.drop1 = Dropout(self.drop_ratio1)
self.fc2 = Linear(in_features=4096, out_features=4096)
self.drop_ratio2 = 0.5
self.drop2 = Dropout(self.drop_ratio2)
self.fc3 = Linear(in_features=4096, out_features=num_classes)
def forward(self, x, label=None):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.conv5(x)
x = F.relu(x)
x = self.max_pool5(x)
# print(x.shape)
x = paddle.reshape(x, [x.shape[0], -1])
# print(x.shape)
x = self.fc1(x)
x = F.relu(x)
# 在全连接层后使用dropout抑制过拟合
x = self.drop1(x)
x = self.fc2(x)
x = F.relu(x)
x = self.drop2(x)
x = self.fc3(x)
x = F.softmax(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
训练10个epoch后,AlexNet的准确率达到了92%。



VGG
VGG模型真的是超级整洁的,满足了强迫症患者的需求!(严重怀疑研究者也有强迫症)

VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。由于使用了较小的卷积核,因此可以堆叠更多的卷积层。
它的代码真的是很整洁,满足了强迫症患者的需要:

在眼疾识别数据集上训练10个epoch后,在验证集上的准确率达到了93%



GoogLeNet
这个GoogLeNet一看就知道是谷歌开发的,而且还蹭了一下LeNet的名字哈哈哈。它是2014年ImageNet的冠军,它和前面这些网络相比,特点就是不仅有“深度”,还具有“宽度”。
由于图像信息的空间尺寸上存在巨大差异,不同尺寸的图像信息适合使用不同大小的卷积核来提取。单一大小的卷积核无法满足要求。这个模型的宽度体现在使用了一种叫做Inception的模块的解决方案。

上面左边的图片就是Inception模块的设计思想了,它使用不同大小的卷积核对图像进行处理,然后拼接成一个输出。这样子就达到了捕捉不同尺度的信息的效果。
Inception模块采用的是多通路的设计,每个支路使用不同大小的卷积核,最终输出的特征图就是每个支路输出通道数的总和。
这里存在一个问题,就是输出的参数量会很大,尤其是多个模块串联的时候。
因此Inception模块采用了上面右图的设计方式,在每个3*3和5*5的卷积层前面加上一个1*1的卷积层来减少输出通道的数量。
下面是GoogLeNet的结构

GoogLeNet在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
- 第一模块使用一个64通道的7 × 7卷积层。
- 第二模块使用2个卷积层:首先是64通道的1 × 1卷积层,然后是将通道增大3倍的3 × 3卷积层。
- 第三模块串联2个完整的Inception块。
- 第四模块串联了5个Inception块。
- 第五模块串联了2 个Inception块。
- 第五模块的后面紧跟输出层,使用全局平均池化层来将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。
PS:图片里面的softmax1和softmax2是辅助分类器,训练的时候将三个分类器的损失函数进行加权求和。这样子的目的是缓解梯度消失现象。
然后,又是训练环节了,经过10个epoch的训练,我们可以看到,在验证集中的准确率达到了96%以上。



ResNet
ResNet“残差神经网络”,它的结构有点恐怖…层数非常的多。

我们知道,当网络层数增加后,训练误差往往不降反升,效果不如之前的。
ResNet的设计思想如下:

上左图表示,增加网络的时候,将x映射成y=F(x),这是传统的神经网络的模式。
上右图对其作了改进,变成了y = F(x)+x,这时,学习的就是y-x。
F(x)=y-x也叫做残差项,如果x➡y的映射接近恒等映射,上面右图通过学习残差项也比学习完整映射形式更加的容易。
上面右边的结构就是残差块,通过将输入x跨层连接,能更快的向前传播数据,或者向后传播梯度。这个过程和“传声筒”是类似的,由于有短路连接的x,每一层都有机会与最终的loss进行“直接对话”,可以更好的解决梯度弥散的问题。
残差块的具体设计就如下图所示了,这种结构是“两头大,中间小”的结构,因此也叫做瓶颈结构。

- 1*1的卷积核是为了调整中间层的通道的数量,在进入3*3的卷积层之间减少通道数量,然后经过该卷积层后,再恢复通道数量。这样子就可以减少网络的参数量。

上图是ResNet-50, 一共有49层卷积和一层全连接,因此被称为ResNet-50
然后,我就把ResNet-50用paddle框架手撕了一遍,在眼疾分类数据集上进行训练,最终得到的在验证集中的准确率大约是94%。

可以发现,尽管层数增加了,但是ResNet的Loss下降的还是比其他神经网络都要快一些,这得益于其残差模块的设计,能使得数据传播的更快。


学习到的一些知识点
- 二分类模型使用SGD可以快速收敛
- 当loss不收敛或者验证集的准确率一直很低的时候,应当尝试更换优化器或者降低学习率。(我就是在这里折腾了很久,发现模型一直准确率很低,loss也不收敛。尝试了很久,也不知道怎么办,后来问了大佬才知道,换个优化器或者Adam降低学习率就能解决这个问题)
- 交叉熵损失函数自带了一个softmax,有些情况下,如果模型的输出已经带上softmax,就有可能导致loss不收敛
转载请注明来源:https://www.longjin666.top/?p=1075
欢迎关注我的公众号“灯珑”,让我们一起了解更多的事物~